SynerComm and ChannelBytes hosted an engaging virtual discussion with Check Point, touching on topics ranging from “Innovative ways Check Point is tackling cloud security issues” to “How does machine learning and AI play into automation?” and “Advice for security teams adopting new security dynamics”.
In this video we’re discussing cloud security in the modern world with SynerComm, a leading security consultant. Our experts dive into developing cloud capabilities and the cybersecurity implications associated with it. Watch and learn from Kirk Hanratty, SynerComm’s CTO and Co-founder, and TJ Gonen, Head of Cloud Security at Check Point.
SynerComm and ChannelBytes hosted an engaging virtual discussion with Expel, touching on topics ranging from “Advancements from SIM technology” to “Email phishing and the cybersecurity lifecycle” and “Implications and threats within IoT”.
In this video we’re discussing the rise and fall of cybersecurity breaches with SynerComm, a leading security consultant. Watch and learn from Kirk Hanratty, SynerComm’s CTO and Co-founder, and Matt Peters, Chief Product Officer at Expel.
SynerComm Inc. is proud to announce it has been named a 2020 “Overall” Partner of the Year by Juniper Networks. Selected out of 1,000 plus Juniper Networks North America Partners, SynerComm has been recognized for exceptional innovation, problem‐solving and customer experience abilities.
“It’s an honor to be recognized by Juniper Networks as 2020 Overall North America Partner of the Year,” says Mark Sollazo, President & CEO, Co‐Founder SynerComm, Inc. “The growth we achieved is a testament to the strength of our partnership with Juniper and sharing common goals for our customers. We are pleased to be recognized for our exceptional innovation, problem‐solving and customer experience.”
Each year, Juniper recognizes partners who have demonstrated innovative solutions to drive new business, delivered exceptional attention to customer experience and have the outstanding ability to solve a multitude of business challenges.
“Juniper Networks is thrilled to recognize SynerComm as a 2020 Overall Partner of the Year for North America. To accomplish this, SynerComm embraced Juniper’s bold standards of superior business agility and ingenuity, and delivered excellent customer outcomes,” says Gordon Mackintosh, Vice President Global Channels & Virtual Sales. “This is a significant achievement, and we are proud of our partnership with SynerComm who continues to set the bar high in experience‐first networking.”
SynerComm leverages the Juniper Networks MIST AI‐driven platforms to drive customer outcomes and experiences. SynerComm focuses on enterprises and service providers multi‐cloud, security infrastructure and information assurance needs powered by SynerComm’s award‐winning Continuous Attack Surface Management CASM Engine™ recently named in the SC Magazine Best Vulnerability Management and Pentest Solution category.
About SynerComm
For years, SynerComm has been making large, global multi‐cloud/hybrid infrastructure design, procurement and deployments simpler and stress free with our ImplementIT staging, localization and logistics services. For more information, visit:
The Journey to the AI-driven Enterprise with Bob Friday, Co-Founder of Mist Systems
#_SHELLNTEL
In penetration testing, it’s important to have an accurate scope and even more important to stick to it. This can be simple when the scope is limited to a company’s internet service provider (ISP) or ARIN provided IP ranges. But in many cases, our client’s public systems have grown to include multiple cloud hosted servers, applications, and services. It may seem obvious to say that anything owned or managed by the company should be in-scope for testing, but how do we know what is “owned" or "managed”? Ideally, we’d test everything that creates risk to an organization, but that isn’t always possible.
I led this article by stating that an accurate scope is critical to penetration testing. If the scope only includes the IP blocks provided by your ISP, you’re probably missing systems that should be tested. Alternately, pentesting a system that you don’t have permission to test could land you in hot water. The good news is that hosting providers like Amazon Web Services (AWS) and Azure allow penetration testing of systems within your account. In other words, because you manage them, you have the right to pentest them. In these environments, pentesting your individual servers (or services) does not affect “neighboring” systems or the cloud host’s infrastructure.
What risks are there?
In addition to the many compute and storage providers, you may also have websites and applications that are hosted and managed by a 3rd party. These still create risk to your company, but the hosting provider has complete control over who has permission to perform testing. When there is custom code or sensitive data at play, you should be seeking (written) permission to pentest/assess these systems and applications. If the host is unable or unwilling to allow testing, they should provide evidence of their own independent testing.
There are also going to be cloud systems that, despite creating risk to your organization, can’t be tested at all. This includes software as a service (SaaS) applications like SalesForce, SAP, and DocuSign.
And you guessed it… there are also systems like Azure AD, Microsoft 365, and CloudFlare that are not explicitly in-scope, but their controls may not be avoidable during external pentests. MS 365 uses Azure AD which is basically a public extension of your on-premise (internal) Active Directory; complete with extremely high-performance authentication services. Most authentication attacks today take place directly against Azure AD due to its performance and public accessibility. In other words, an attacker could have your passwords before they ever touch a system on your network. Likewise, if your company uses CloudFlare to protect your websites and web applications, it inherently becomes part of the scope because testing of these apps should force you through their proxy/control.
Next steps
Hopefully this information will help you plan for your next pentest or assessment. If your company maintains an accurate inventory of external systems that includes all of your data center and cloud systems, you’re already off to a great start. Still, there is always value in doing regular searches and discoveries for systems you may be missing. One method involves reviewing your external DNS to obtain a list of A and CNAME records for your domains. (For ALL of your domains…) By resolving all of your domains and subdomains you can easily come up with a pretty large list of IP addresses that are in some way tied to your company. Now all you need to do is lookup each IP to see what it’s hosting and who owns it. Easy right?
If you don’t already have a tool for looking up bulk lists of IP addresses or you prefer not to paste a list of your company’s IP addresses into someone else’s website, we’ve got a solution. Whodat.py was written to take very large lists of IP addresses and perform a series of whois and geoip lookups. If the IP address is owned by Amazon or Microsoft, additional details on the service or data center get added based the host’s online documentation. This tool was designed for regular use by our penetration testers, but its concepts and capabilities are a core functionality of our CASM Engine™ and our suite of Continuous Attack Surface Management and Continuous Penetration Testing subscriptions.
One of the things I have noticed while working at SynerComm over the years is that while most companies have employees on staff who possess the necessary technical knowledge to complete their projects, many organizations lack the logistics knowledge that large‐scale deployments require. As such, many companies typically rely on their project managers to handle these deployments. While project managers possess a wide variety of skills, few have extensive experience handling the logistics of large, complex deployments and could benefit from some expert advice and assistance.
To fill this knowledge gap and help our partners succeed, SynerComm created ImplementIT, a production‐readiness approach that offers smooth deployments for IT organizations looking to scale their operations.
Handling the Logistics of Large-Scale Deployments: Tips for IT Personnel & Project Managers
Experts like the team at SynerComm can help you define, model, and analyze your options when it comes to procurement, staging, testing, coordination, shipping, installation, and support. Even if you ultimately decide not to partner with an external logistics team, your organization can still benefit from their advice and learn how to avoid many of the common pitfalls associated with large, complex deployments that unprepared teams are more likely to encounter.
The SynerComm team is always happy to help and appreciates the opportunity to help organizations consider all their options and plan their approach to any large, complicated deployment. Though each project has unique factors that need to be considered, many deployment projects share at least some similarities. An impact and approach analysis conducted with help from the experts is a small investment that can save your organization time and money while minimizing frustrating delays and other challenges.
The Benefits of ImplementIT
ImplementIT has been specifically designed to help set project managers, and their projects, up for success by offering advice as well as practical assistance.
To help ensure each deployment goes smoothly, all ImplementIT customers are assigned their own SynerComm project manager. All of our project managers are trained to blend well with your PMO requirements while bringing recent and relevant logistics experience to the table. They also have extensive experience managing and mitigating the common risks and issues frequently associated with shipping (particularly international shipping), as well as the skills required for country‐specific installation and support.
ImplementIT project managers are able to integrate seamlessly with your organization, expanding your team’s capabilities when it comes to large‐scale, geographically diverse, and complex deployments. Your ImplementIT project manager is there to help you make decisions and avoid potentially costly and time‐consuming issues. Our culture of collaboration and transparency means we gladly share our knowledge freely, setting PMOs up for success and teaching them the skills they need to handle future deployments on their own while also offering ongoing support and advice as requested.
The ImplementIT Process
The first thing we do before we begin any logistically challenging IT project is sit down with your project managers to ensure we understand your schedule and your outcome requirements. Once we are certain we are all striving towards the same goal, we identify atomic units for the project, including sites, systems, and milestones, and define the high‐level breakdown structure required to manage the deployment of those units. During this phase, we also take into account all related activities, communications, and deliverable to help ensure the deployment goes as smoothly as possible.
Once all parties are on the same page regarding those higher‐level concepts, our team begins codifying these concepts into a working model. This includes layering in details and assumptions based on our extensive experience and capturing the supporting variables for common decision sets. This model allows our team to work closely with your team so we can effectively communicate and explain cost, quality, and schedule expectations based on our expert assumptions.
Working together, we begin changing the variable decision points in order to gain an immediate understanding of what the impact of various decisions might be. By working together through the options using real‐time impact information, the two teams can co‐author an approach that is mindful of your project's unique considerations. We also work to create a solid rapport and establish open lines of communication between both teams early on in the project. This helps minimize the chance of unwelcome surprises, ensuring we consider all possible options and setting the project up for success. In an effort to avoid unpleasant surprises and ensure the deployment goes as smoothly and seamlessly as possible, we try to ensure all assumptions, risk, deliverables, schedules, measures, and metrics are clearly understood on both sides upfront.
Why Risk & Issue Management is Vital to Project Success
As an IT and logistics professional, I can never emphasize enough the value of a solid approach to risk and issue management. Most large‐scale deployments need to be deployed to hundreds or even thousands of sites and require the coordinated cooperation of dozens of teams and individuals. As such, no deployment is ever completely issue‐free.
Common issues I have encountered over the course of my career include:
Design and configuration requirements changing mid‐project
Unforeseen post‐deployment technical issues
The key to keeping any project on track and progressing smoothly is complete visibility. We have achieved this by creating a single secure portal that handles all tracking, reporting, documentation, testing, and communication. By ensuring all critical information and communication occurs through a single, centralized portal such as the one ImplementIT leverages, we can help ensure that all key stakeholders are on the same page at all times and have total visibility into all aspects of the project.
By leveraging SynerComm’s full team of highly qualified IT and logistics staff, you don’t need to redeploy valuable, internal IT staff to handle “rinse and repeat” style deployments. This means that your internal IT professionals can continue to focus on higher‐impact projects and activities designed to grow and safeguard your business.
ImplementIT combines the indispensable technical knowledge of qualified IT professionals with the critical skills required to smoothly and seamlessly handle large‐scale, complex deployments, allowing you and your team to focus on what matters most: your business.
For more information about ImplementIT, or to get started on your next large‐scale deployment, please contact us today.
Although contingency planning has a healthy focus on technology, it still requires people to interface with that technology, configure and program the technology so that it will perform some productive task, as well as a number of other roles. In truth, due to the ubiquity of technology within any business, contingency planning is a company-wide effort. Not only the planning, but the execution of the plan at any level will require the cooperation of business managers and technology managers. What needs to be understood is that contingency planning, from a business perspective, is a vital part of COOP. Within COOP and information security contingency planning is where the procedures on addressing a pandemic should be placed. Information system contingency plans, as well as COOP, cannot be created in a vacuum, as their scope impacts the entire organization. This is a primary driver for the need to ensure these plans are officially recognized and distributed to all parts of the company. A good source of information on how to address contingency planning can be found in the National Institute of Standards and Technology (NIST) publications, which is where much of the following guidance can be found.
Pandemic Contingency Plan
Pandemic contingency actions, as it may appear obvious now, focus on protecting the workforce while still conducting some form of business operations. When an incident occurs that impacts organization’s personnel, it likely will impact the information system operations. A prime example of this, seen with COVID-19, was the sudden, immediate need for staff to work remotely. This step is clearly linked to proper considerations for the safety, security, and well-being of personnel during a disruptive event, which is a goal of contingency planning. Organizations should also have in place methods and standards for sending out responsive messages to personnel, as well as considerations for responding to media inquiries on the topic of staff safety and ongoing operations. Considering the heightened awareness of these issues due to COVID-19 and general increased security throughout our society, personnel considerations for staff warrant discussion in all contingency planning related areas.
The organization’s COOP and contingency plan should contain the steps and details to address how the organization will:
Protect employees wellbeing during a pandemic
Sustain essential business functions during significant times of absenteeism
Support the overall national and global response during a pandemic
Communicate guidance and support to stakeholders during a pandemic
Pandemic Unique Considerations
As we have seen with the COVID-19 response, common strategies to protect personnel health during a pandemic outbreak include more strict hygiene precautions and a reduction in the number of personnel working in close contact with one another through the implementation of “social distancing.” To address this challenge, organizations need to have in place approved telework arrangements to facilitate social distancing through working at home while sustaining productivity.
In some situations, organizations may need to use personnel from associated organizations or contract with vendors or consultants if staff are unavailable or unable to fulfill responsibilities. Preparations should be made during contingency planning development for this possibility to ensure that the vendors or consultants can achieve the same access as staff in the event of a pandemic. Once personnel are ready to return to work, if the facility is unsafe or unavailable for use, arrangements should be made for them to work at an alternate site or at home. This should be an alternate space in addition to the alternate site for information system recovery. Personnel with home computers or laptops should be given instruction, if appropriate, on how to access the organization’s network from home.
Significant events like COVID-19 take a heavy psychological toll on personnel. Employee Assistance Programs (EAP) should be considered as a useful and confidential resource to address these issues. Nonprofit organizations, such as the American Red Cross, also provide referrals for counseling services as well as food, clothing, and other assistance programs. Personnel generally will be most interested in the status of the health benefits and payroll. It is very important that the organization communicate this status.
The Key – Prior Planning
In addition to the above, the best way to prepare for a possible pandemic health crisis really comes down to planning carefully. Once a plan has been assembled, not only do you want to be sure that it is stored in a secure location, but also have copies appropriately distributed. A crucial component of these contingency plans is that they are reviewed on an annual basis to address changes that occur over time. Be sure that your contingency plan includes:
Reviewing relevant policies and practices from authoritative sources, such as government agencies. In the case of COVID, reviewing information from the Centers for Disease Control and Prevention (CDC), would be pertinent.
Developing human resources management strategies to deal with circumstances that may arise during a pandemic health crisis.
Testing plans of action and telecommunication systems to ensure readiness.
Communicating with employees, managers, and other stakeholders prior to, during, and after the pandemic health crisis.
When planning, one of the first, and an important element that can be difficult to get your arms around, is “who will be responsible for what?”. Generally speaking, organizations should rely on their business unit structure to help identify where specific tasks should fall. This straight-forward approach should be a first step and will likely identify that most operations will remain within the same unit – it will be critical to review those operations to ensure that inter-departmental support from other areas are not required. There are additional overarching principles for roles and responsibilities that will need to be clearly defined for this plan. When planning for overall roles and responsibilities, areas to consider here are:
Organization Roles and Responsibilities
Provide resources for training and testing
Ensure communication systems work
Develop guidance on protecting sensitive information and providing for contingency hiring
Supervisory Roles and Responsibilities
Plan for short and long-term disruptions
Stay in constant touch with employees and leadership
Develop guidance on protecting sensitive information and providing for contingency hiring
Employee Roles and Responsibilities
Be ready for alternative work arrangements
Protect sensitive information
Stay in constant touch with management
If these considerations are not part of your overall contingency plan for pandemic response, review and see where they might fit best in the existing framework. If you were one of the many organizations that were caught off-guard by the needed actions to address COVID-19, this should help as a starting point for structuring future plans. What can not be over-stated is that the time to act and produce a relevant contingency plan and COOP is now.
Contact SynerComm to find out how our consultants can assist with not only the pandemic contingency planning, but with technical support and guidance in the areas of hardware, software and networking.
“So, let’s say we fix all of the vulnerabilities that the pentest discovers… How do we know tomorrow that we’re not vulnerable to something new?”
~Customer
Bridging the Gap Between Point-in-Time Penetration Tests
Having been part of the penetration testing industry for over 15 years, I’ve been challenged by many clients with this very question. The fact is that they are right, a penetration test is a point-in-time assessment and new vulnerabilities are discovered every day. We hope that our patch and vulnerability management processes along with our defensive controls (firewalls, etc.) keep our systems secure. Over the past 5 years, we’ve experienced a rise in the number of clients moving towards quarterly penetration testing and seeing the value of rotating through different penetration testers.
In 2017, SynerComm’s penetration testers decided to put their heads together to develop an even better solution. (Honestly, one of our top guys had been nudging me for two years with an idea already…) We agreed that nothing replaces the need for regular human-led penetration testing. As of today, no amount of automation or AI can come close to replicating the intuition and capabilities of an actual penetration tester. That said, if we can be confident that nothing (ok, very little) has changed since the last penetration test, we can be significantly more confident that new vulnerabilities are not present. Building on this idea, the continuous pentest was born.
Continuous Pentesting
Continuous pentesting combines the best of both worlds by using automation to continually monitor for changes, and human pentesters to react to those changes quickly. Computers are great at monitoring IP addresses, services, websites, and DNS. They can also monitor breaches and data dumps for names, email addresses, and passwords. What makes continuous pentesting successful, is taking actions based on changes and using orchestration to determine if additional scans can be run and if a pentester should be alerted.
There is no replacement for the validation provided by a thorough, skilled, and human-led penetration test. External and internal pentests with social engineering demonstrate precisely how a determined and skilled intruder could breach your company’s systems and data. Continuous Penetration Testing focuses on public systems and online exposures and should always follow a full, human-led, external penetration test. Partner with SynerComm and we’ll keep an eye on your perimeter security year-round.
Palo Alto Networks firewalls have the ability to create security policies and generate logs based on users and groups, and not just IP addresses. This functionality is called User-ID.
User-ID™ enables you to map IP addresses to users on your network using a variety of techniques. The methods include using agents, monitoring domain controller event logs, monitoring terminal servers, monitoring non-AD authentication servers and syslog servers, and even through captive portals (that prompt the user for login). In addition to its use in policies, logging access and threats by user can be invaluable in incident response and forensics. To take full advantage of this feature, it is ideal to map as many IP addresses to users as possible.
With all these great methods to map users to IP addresses, we often miss many systems. They include non-domain joined systems, Linux/Unix systems that don’t centrally authenticate, and potentially many other devices (phones, cameras, etc.). Palo Alto has yet another feature for mapping users, but one that comes with great risk.
To identify mappings for IP addresses that the agent didn’t map, the firewall can probe and interrogate devices. The intention is to only probe systems connected to trusted internal zones, but a misconfigured zone could even allow sending probes out to the internet. Taking that misconfiguration aside, client probing is still a significant security risk. By default, Palo Alto agents send out a request every 20 minutes to all IP addresses that were recently logged but not mapped to a user. It does this assuming that the IP belongs to a Windows system and it uses a WMI probe to log into the unmapped system.
SynerComm believes that a large number of PAN
customers have enabled WMI and/or NetBIOS Client Probing within the User-ID
settings. Our AssureIT penetration
testing team is regularly detecting this on internal pentests. SynerComm
recommends disabling Client Probing in the User-ID Agent setup due to the risk.
The Vulnerability:
Many networking
and network security devices use Microsoft WMI probing to interrogate Windows
hosts for things like collecting user information. For authentication
purposes, a WMI probe contains the username and hashed password of the service
account being used. When a domain account is used, an NTLMv1 or NTLMv2
authentication process takes place. It
has come to our attention that our penetesters are finding Palo Alto firewalls
that are using insecure User-ID methods. Specifically, those that are using WMI
and NetBIOS probes to attempt user identification. This allows an
attacker to obtain the service account’s username, domain name, and the
password hash (more likely the hashed challenge/nonce). Because the service
account requires privileges, this becomes a serious security exposure that
could be easily abused.
An October 30,
2019 Palo Alto Advisory “Best Practices for Securing User-ID
Deployments” recommends ensuring that User-ID is
only enabled on internal/trust zones, and applying the principal of least
privilege for the service account. Again
though, SynerComm recommends also disabling WMI probing completely.
The Attack….
(By: Brian Judd, VP
Information Assurance)
In a perfect world, we could trust that every device on
our internal network is owned, managed, and monitored by our company and our
staff. That includes having full trust that no systems are already compromised,
and that no intruder or insider could place a rogue device on our network.
Because this is rarely, if ever the case, it’s a stretch to think that it’s
safe to share valid domain credentials with any device connected to an internal
network.
Using well-known penetration testing tools like
responder.py, it is trivial to setup a SMB server that that can listen for and
respond to NTLM authentication requests. When good OPSEC isn’t a factor,
responder.py also includes abilities to respond to LLMNR and NetBIOS broadcasts
to poison other local systems into authenticating to its listening SMB server.
It then stores the username and the hashed challenge (nonce) from the
authentication messages. Depending on the strength of the password, these
captured “hashes” could be cracked and the account could be used to log into
other systems.
While all of that sounds scary, it isn’t the concern of
this article. If configured to use “Client Probing”, Palo Alto firewalls and
their User-ID agents make WMI and NetBIOS connections to map unknown IP
addresses to their logged in user. Also, because WMI is IP based, it’s possible
to probe any reachable (retable) network/system. To be effective, User-ID
almost always uses a domain service account so that it can access any domain
member system. An attacker with the ability to run responder.py on an internal
network is likely to receive authentication requests from Palo Alto User-ID
agents without any need for noisy poisoning attacks. By default, the agent
probes every 20 minutes and anytime a new log is written to the firewall
without user identification.
OK, let’s make this a bit worse… What if we didn’t need
to crack the service account’s password? What if we could just relay the
agent’s authentication request to another system and trick it into
authenticating the attacker instead? Again, this is trivial and easy using
well-known tools like ntlmrelayx.py or MultiRelay.py. Even worse, these tools
are not exploits, this is how NTLM authentication was designed to work. If the
relayed account’s privilege is sufficient, ntlmrelayx.py will even dump the
system’s stored hashes from the SAM database, or execute shell code.
Oh, remember earlier when I mentioned that Palo Alto’s
agent probes anytime a new log is written by an unmapped IP address? Using this
“feature”, we can script something as simple as a DNS lookup or wget request to
generate access logs on the firewall and trigger a User-ID authentication
request. With a little time, these logins could be relayed to log into every
other system on the network. Considering that older Palo Alto documentation was
vague with regards to the necessary service account privileges, it is common to
find them as members of highly privileged groups including Domain
Administrators. To an attacker, this could be game, set, match in just a few
minutes.
SynerComm Recommends:
Disable (Do NOT Enable) Client Probing within Palo Alto’s User-ID Agent configuration
Didn’t you read the title of this article, “Stop Sharing Your Password with Everyone”
Ensure that User-ID is only enabled on trusted internal zones and further restrict it to the specific source IP addresses of its agents
Set a very strong random password for the User-ID agent’s service account
20 characters is usually sufficient, but it’s always ok to make it longer!
Enable SMB Signing on Windows workstations and servers
While not specific to Palo Alto, this control prevents most NTLM relaying attacks
Disable LLMNR and NetBIOS in the local security settings of Windows operating systems
Again, nothing to do with Palo Alto, but this prevents LLMNR and NetBIOS poisoning attacks
Disable NTLMv1 and NTLMv2 authentication
Kerberos can replace NTLM, but it’s not backwards compatible with older operating systems. Be sure to research and test first, and always have a backout plan.
Perform annual internal and external penetration tests to uncover hidden weaknesses that leave your networks and systems vulnerable to attack
Palo Alto User-ID Security Best Practices
Specify included and excluded networks
when configuring User-ID
The include and exclude lists available on the User-ID
Agent, as well as agentless User-ID, can be used to limit the scope of User-ID.
Typically, administrators are only concerned with the portion of IP
address space used in their organization. By explicitly specifying
networks or preferably a host address /32, to be included with or excluded from User-ID,
we can help to ensure that only trusted and company-owned assets are probed,
and that no unwanted mappings will be created unexpectedly. See above image.
Disable WMI and NetBIOS Client Probing
WMI, or Windows Management Instrumentation, is a
mechanism that can be used to actively probe managed Windows systems to learn
IP-user mappings. Because WMI probing trusts data reported back from the
endpoint, it is not a recommended method of obtaining User-ID information in a
high security network. In environments containing relatively static
IP-user mappings, such as those found in common office environments with fixed
workstations, active WMI probing is not needed. Roaming and other
mobile clients can be easily identified even when moving between addresses by
integrating User-ID using Syslog or the XML API and can capture IP-user
mappings from platforms other than Windows as well.
On sensitive and high security networks, WMI probing
increases the overall attack surface, and administrators are recommended to
disable WMI probing and instead rely upon User-ID mappings obtained from more
isolated and trusted sources, such as domain controllers.
If you are using the User-ID Agent to parse AD security
event logs, syslog messages, or the XML API to obtain User-ID mappings, then
WMI probing should be disabled. Captive portal can be used as a fallback
mechanism to re-authenticate users where security event log data may be stale.
Use a dedicated service account for
User-ID services with the minimal permissions necessary
User-ID
deployments can be hardened by only including the minimum set of permissions
necessary for the service to function properly. This includes DCOM
Users, Event Log Readers, and Server Operators. If the User-ID service
account were to be compromised by an attacker, having administrative and other
unnecessary privileges creates significant risk. Domain Admin and
Enterprise Admin privileges are not required to read security event
logs and consequently should not be granted.
Deny interactive logon for the User-ID
service account
While the User-ID service account does require certain
permissions in order to read and parse Active Directory security event logs, it
does not require the ability to log on to servers or domain systems
interactively. This privilege can be restricted using Group Policies, or
by using a Managed Service Account with User-ID (See Microsoft TechNet for more
information on configuring Group Policies and Managed Service Accounts.)
If the User-ID service account were to be compromised by a malicious user, the impact
could be reduced by denying interactive logons.
Deny remote access for the User-ID
service account
Typically, service accounts should not be members of any security
groups that are used to grant remote access. If the User-ID service account
credentials were to be compromised, this would prevent the attacker from using
the account to gain access to your network from the outside using a VPN.
Configure egress filtering
Prevent any unwanted traffic (including potentially
unwanted User-ID Agent traffic) from leaving your protected networks out to the
Internet by implementing egress filtering on perimeter firewalls
Additional Information
For more information on setting up and configuring User-ID see the following or contact SynerComm today:
One of the greatest yet unknown dangers that face any cloud-based application is the combination of an SSRF vulnerability and the AWS Metadata endpoint. As this write up from Brian Krebbs explains, the breach at Capital One was caused by an SSRF vulnerability that was able to reach the AWS Metadata endpoint and extract the temporary security credentials associated with the EC2 instance's IAM Role. These credentials enabled the attacker to access other Capital One assets in the cloud and the result was over 100 million credit card applications were compromised.
The Vulnerabilities
In order to fully understand the impact of this cloud one-two punch it is necessary to break down the attack chain into its various components: SSRF and the AWS Metadata Endpoint. First, Server Side Request Forgery (SSRF) is a vulnerability that allows an attacker to control the destination address of an HTTP request sent from the vulnerable server. While this is not always the case (see Blind SSRF), the attacker can often see the response from the request as well. This allows the attacker to use the vulnerable server as a proxy for HTTP requests which can result in the exposure sensitive subnets and services.
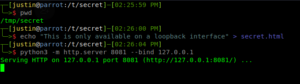
The code above sends an HTTP request to the hostname specified by the attacker in the "hostname" GET parameter. Logic like this is commonly found in the "Integrations" section of applications. This code is vulnerable to SSRF. Consider the following scenario: There is a sensitive service running on the loopback interface of the vulnerable server. This is emulated by the following configuration:
The PHP code above is hosted on the web server that faces the internet. When an attacker discovers this endpoint, he/she might use the following to grab the data from the internal application:
Now that the danger of SSRF is clear, let's look at how this vulnerability may be exploited in the context of the cloud (AWS in particular).
Due to the dynamic nature of the cloud, it became necessary that server instances (EC2 for example) have some way to get some basic information about their configuration for the purpose of orienting themselves to the environment in which they were spun up. Out of this need, the AWS Metadata endpoint was born. This endpoint (169.254.169.254), when hit from any EC2 instance, will reveal information about the configuration of the particular EC2 instance. There is quite a lot of information available via this endpoint including: hostname, external ip address, metrics, lan information, security groups, and the IAM (Identity and Access Management) credentials associated with this EC2 instance. It is possible to retrieve these security credentials by hitting the following URL where [ROLE] is the IAM role name:
The response contains several things: the AccessKeyId, SecretAccessKey, and the Token for this account. Using these credentials, an attacker can login to AWS and compromise the server and potentially many other assets. In the case of the Capital One breach, these credentials were used to access an S3 bucket which contained millions of records of user information.
In summary, the poor implementation of the metadata service in AWS allows for an attacker to easily escalate an SSRF vulnerability to control many different cloud assets. Other cloud providers like Google Cloud and Microsoft Azure also provide access to a metadata service endpoint but requests to these endpoints require a special header. This prevents most SSRF vulnerabilities from accessing the sensitive data there.
How to prevent such a vulnerability
In order to prevent this type of vulnerability from occurring firewall rules will need to be put in place to block off the metadata endpoint. This can be done using the following iptables rule:
sudo iptables -A OUTPUT -d 169.254.169.254 -j DROP
This will prevent any access to this ip address. However, if access to the metadata endpoint is required, it is also possible to exclude certain users from this rule. For example, the iptables rule below would allow only the root user to access the metadata endpoint:
sudo iptables -A OUTPUT -m owner ! --uid-owner root -d 169.254.169.254 -j DROP
These blocks MUST be done at the network level - not the application level. There are too many ways to access this IP address. For example, all of these addresses below refer to the metadata service:
http://[::ffff:169.254.169.254]
http://[0:0:0:0:0:ffff:169.254.169.254]
http://425.510.425.510/ Dotted decimal with overflow
http://2852039166/ Dotless decimal
http://7147006462/ Dotless decimal with overflow
http://0xA9.0xFE.0xA9.0xFE/ Dotted hexadecimal
http://0xA9FEA9FE/ Dotless hexadecimal
http://0x41414141A9FEA9FE/ Dotless hexadecimal with overflow
http://0251.0376.0251.0376/ Dotted octal
http://0251.00376.000251.0000376/ Dotted octal with padding
http://169.254.169.254.xip.io/ DNS Name
http://A.8.8.8.8.1time.169.254.169.254.1time.repeat.rebind.network/ DNS Rebinding (8.8.8.8 -> AWS Metadata)
And there are many more. The only reliable way to address this issue is through a network level block of this IP.
The easiest way to check the IAM roles associated with each EC2 instance is to navigate to the EC2 Dashboard in AWS and add the column "IAM Instance Profile Name" by clicking the gear in the top right hand corner. Once the IAM role for each EC2 instance is easily visible, it is possible to check these roles to see if they are overly permissive for the what is required of that EC2 instance.
It is also imperative to understand the pivoting potential of these IAM Roles. If it is possible that an SSRF, XXE, or RCE vulnerability was exploited on any cloud system, the logs for the IAM Role associated with this instance must be thoroughly audited for malicious intent. To avoid a breach like Capital One, reach out to SynerComm.
Background
While experts have agreed for decades that passwords are a weak method of authentication, their convenience and low cost has kept them around. Until we stop using passwords or start using multi-factor authentication (for everything), a need for stronger passwords exists. And as long as people create their own passwords that must be memorized, those passwords will remain weak and guessable. This blog/article/rant will cover a brief background of password cracking as well as the justification for SynerComm’s 14-character password recommendation.
First
things first: What is a password?
Authentication is the process of verifying the identify of a user or process, and a password is the only secret “factor” used in authentication. For the authentication process to be trusted, it must positively identify the account owner and thwart all other attempts. This is critical, because access and privileges are granted based on the user’s role. Considering how easily passwords can be shared, most have already concluded that passwords are an insufficient means of authenticating people. We must also consider that people must memorize their password and that they often need passwords on dozens if not hundreds of systems. Because of this, humans create weak, easily guessed, and often reused passwords.
Password
Controls
Over the years, several password controls have emerged to help strengthen password security. This includes minimum password length, complexity, preventing reuse, and a reoccurring requirement to create new passwords. While it is a mathematical fact that longer passwords and a larger key space (more possible characters) do indeed create stronger passwords, we now know that regularly changing one’s password provides no additional security control. In fact, forcing users to regularly create new and complex passwords weakens security. It forces users to create guessable patterns or simply write them down. OK, I will stop here, we'll save the ridiculousness of password aging for a future blog.
So
Why 14 Characters?
So why is 14 characters the ideal or best recommended password
length? It is not. It is merely a minimal length; we still prefer to see people
using even longer passwords (or doing better than passwords in the first
place). SynerComm recommends a 14-character minimum for several reasons. First,
14-character passwords are very difficult to crack. Most passwords containing 9
characters or less can be brute-force guessed in under 1 day with a modern
password cracking machine. Passwords with 10-12 characters and even 13-14
characters can still be easily guessed if they are based on a word and a
4-digit number. (Consider Summer2018! or your child’s name and birthday.) Next,
and perhaps more importantly, 14-character minimums will prevent bad password
habits and promote good ones. When done with security awareness training, users
can be taught to create and use passphrases instead of passwords.
Passphrases can be sentences, combinations of words, etc. that can be
meaningful and easy to remember. Finally, 14 characters is the largest “Minimal
Password Length” currently allowed by Microsoft Windows. While Windows supports
very long passwords, it is not simple to enforce a minimum greater than 14
characters (PSOs can be used to increase this in Windows 2008 and above, and registry
hacks from anything older, but it can be a tedious process and introduces
variables into the management and troubleshooting of your environment).
The remainder of this article provides facts and evidence to support our recommendations.
Analysis
of Password Length
SynerComm collected over 180,000 NTLM password hashes from various breached domain controllers and attempted to crack them using dictionary, brute-force, and cryptanalysis attacks. The chart below shows the password lengths of the over 93,000 passwords cracked. It is interesting to find passwords that fall drastically below the usual minimum length of eight characters. Although few, it is also worth noting that 20, 21 and 22-character passwords (along with one 27-character password) were cracked in these analyses.
Passwords Cracked = 93,706. Total unique entries of those passwords cracked = 68,161
Passwords of 9 or fewer characters account for 50% of those cracked; 12 or fewer, 75%
Password Length - Number of Cracked Passwords
1 = 3 (0.0%)
2 = 2 (0.0%)
3 = 137 (0.15%)
4 = 27 (0.03%)
5 = 405 (0.43%)
6 = 1527 (1.63%)
7 = 3827 (4.08%)
8 = 26191 (27.95%)
9 = 23677 (25.27%)
10 = 17564 (18.74%)
11 = 9098 (9.71%)
12 = 6267 (6.69%)
13 = 2915 (3.11%)
14 = 1063 (1.13%)
15 = 577 (0.62%)
16 = 276 (0.29%)
17 = 81 (0.09%)
18 = 39 (0.04%)
19 = 13 (0.01%)
20 = 10 (0.01%)
21 = 1 (0.0%)
22 = 4 (0.0%)
23 = 0 (0.0%)
24 = 0 (0.0%)
25 = 0 (0.0%)
26 = 1 (0.0%)
27 = 1 (0.0%)
Analysis of Password Composition
*Note: The password "acme" was used to replace specific company names. For example, if the password "synercomm123$" would have been found in a SynerComm password dump it would have been replaced with "acme123$". This change occurred only to serve the top 10 password and base word tables. Analyses of length and masks were performed without this change.
Top 10 passwords
Password1 = 543 (0.58%)
Summer2018 = 424 (0.45%)
Summer18 = 395 (0.42%)
acme80
= 368 (0.39%)
Fall2018 = 362 (0.39%)
Good2go = 350 (0.37%)
yoxvq = 345 (0.37%)
Gr8team = 338 (0.36%)
Today#08 = 308 (0.33%)
Spring2018 = 219 (0.23%)
Top 10 base words
password = 1993 (2.13%)
summer = 1663 (1.77%)
acme
= 1619 (1.73%)
spring = 734 (0.78%)
fall = 706 (0.75%)
welcome = 652 (0.7%)
winter = 577 (0.62%)
w0rdpass = 562 (0.6%)
good2go = 351 (0.37%)
yoxvq = 345 (0.37%)
Last 4 digits (Top 10)
2018 = 3037 (3.24%)
2017 = 821 (0.88%)
1234 = 733 (0.78%)
2016 = 659 (0.7%)
2015 = 588 (0.63%)
2014 = 561 (0.6%)
2013 = 435 (0.46%)
2012 = 358 (0.38%)
2010 = 296 (0.32%)
2019 = 286 (0.31%)
Masks (Top 10)
?u?l?l?l?l?l?d?d (6315) (8 char)
?u?l?l?l?l?l?d?d?d?d (4473) (10 char)
?u?l?l?l?l?l?l?d?d (4021) (9 char)
?u?l?l?l?d?d?d?d (3328) (8 char)
?u?l?l?l?l?d?d?d?d (2985) (9 char)
?u?l?l?l?l?l?l?l?d?d (2742) (10 char)
?u?l?l?l?l?l?l?d (2601) (8 char)
?u?l?l?l?l?l?l?l?d (2371) (9 char)
?u?l?l?l?l?l?l?d?d?d?d (1794) (11 char)
?u?d?d?d?d?d?d?d?d (1756) (9 char)
Password Hash Cracking Speeds
When performing our own password cracking, SynerComm uses a modern password cracker built with 8 powerful GPUs. Typically used by gamers to create realistic three-dimensional worlds, these graphics cards are remarkably efficient at performing the mathematical calculations required to defeat password hashing algorithms. Most 8-character passwords will crack in 4.5 hours or less. While the same attack against a 9-character password could take up to 18 days to complete, we can reduce the key space (possible characters used in passwords) and complete 10-11 character attacks in just 1-2 days or less.
Password Best Practices
Do not share your password with anyone!
Do not store passwords in spreadsheets, documents, or email! Also avoid storing passwords in your browser (IE, Firefox, Chrome).
Create passphrases instead of passwords. Long passwords are always stronger than short passwords. Passwords shorter than 10 characters can be easily and quickly cracked if their hashes become available to the attacker. SynerComm recommends enforcing at least a 12-character minimum for standard user accounts but suggests using a 14-character minimum to promote good password creation methods. Privileged accounts such as domain administrators should have even longer passwords.
While password complexity is less critical with long (>=14 char) passwords, it still helps ensure a larger key space. Encourage users to use less common characters such as spaces, commas, and any other special character found on the keyboard. (Spaces can make an enormous difference!)
Never reuse the same password on multiple accounts. While it is easier to remember 1 password than 100, our next best practice will provide a solution to that problem too. Dumps containing passwords from breaches are great starting places to guessing a user’s password.
Use a password safe. Modern password managers can sync stored passwords between computers and mobile devices. By using a safe, most users only need to remember 2-3 passwords and the rest can be stored securely in a safe.
When using a safe, it is best practice to allow the application to generate most passwords. This way you can create 15-20 character completely random passwords that you never need to know or memorize.
Implement multi-factor authentication whenever possible. Passwords will always be a weak and vulnerable form of authentication. Using multi-factor greatly reduces the chances of a successful authentication attack. Multi-factor authentication should be used for ALL (no exceptions) remote access and should increasingly be considered for ALL privileged account access.
*For shared accounts (root, admin, etc.), restrict the number of people who have access to the password. Change these passwords anytime someone who could know the password leaves the organization.
~Brian Judd (@njoyzrd) with password analysis by Chad Finkenbiner
From design to deployment to troubleshooting and everything in between, the friendly experts at SynerComm are always here to help.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok